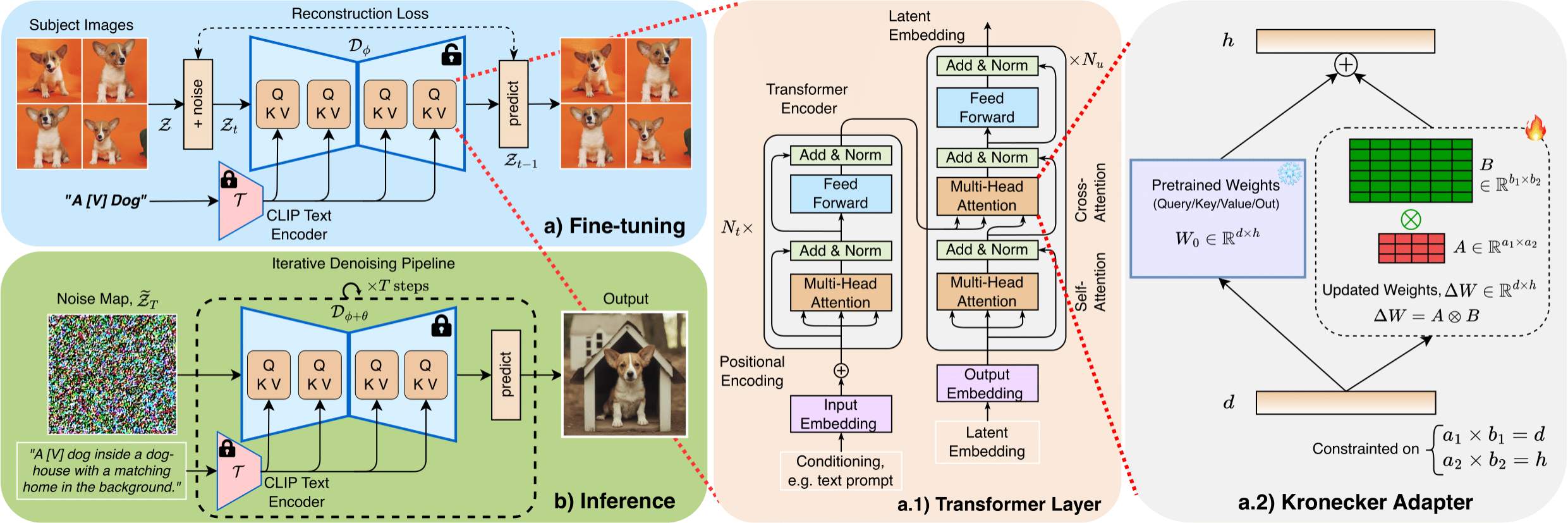
In the realm of subject-driven text-to-image (T2I) generative models, recent developments like DreamBooth and BLIP-Diffusion have led to impressive results yet encounter limitations due to their intensive fine-tuning demands and substantial parameter requirements. While the low-rank adaptation (LoRA) module within DreamBooth offers a reduction in trainable parameters, it introduces a pronounced sensitivity to hyperparameters, leading to a compromise between parameter efficiency and the quality of T2I personalized image synthesis.
Addressing these constraints, we introduce DiffuseKronA, a novel Kronecker product-based adaptation module that not only significantly reduces the parameter count by up to 35% and 99.947% compared to LoRA-DreamBooth and the original DreamBooth, respectively, but also enhances the quality of image synthesis. Crucially, DiffuseKronA mitigates the issue of hyperparameter sensitivity, delivering consistent high-quality generations across a wide range of hyperparameters, thereby diminishing the necessity for extensive fine-tuning.
Evaluated against diverse and complex input images and text prompts, DiffuseKronA consistently outperforms existing models, producing diverse images of higher quality with improved fidelity and a more accurate color distribution of objects, thus presenting a substantial advancement in the field of T2I generative modeling.